概念
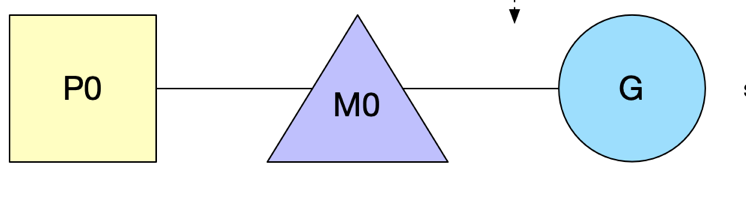
- G:goroutine
- P:它代表了 M 所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接 M 和 G 的调度上下文,将等待执行的 G 与 M 对接。
- M:工作线程
调度模型
1. 创建idle p(GOMAXPROCS)
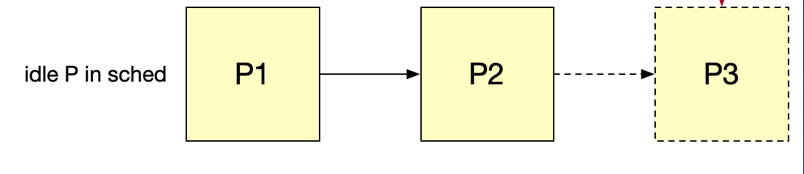
2. 主线程运行: 创建P,绑定P0与M0
3. 创建一个goroutine
- Wakeup 唤醒机制:有空闲的 P 而没有在 spinning 状态的 M 时候, 需要去唤醒一个空闲(睡眠)的 M 或者新建一个。当线程首次创建时,会执行一个特殊的 G,即 g0,它负责管理和调度 G。
- goroutine创建完后,会尝试放在当前P的local queue,如果local queue已满(256),将本地队列的前半部分及新建的goroutine迁移到全局队列。
4. 抢占任务
- 由于3 创建的goroutine可能在本地队列或全局队列,此时新创建的P本地队列为空,这次新的M对执行g0代码,企图去找任务。
- 当一个 P 执行完本地所有的 G 之后,会尝试挑选一个受害者 P,从它的 G 队列中窃取一半的 G。当尝试若干次窃取都失败之后,会从全局队列中获取(当前个数/GOMAXPROCS)个 G。 为避免全局队列饥饿,P 的调度算法中还会每个 N 轮调度之后就去全局队列拿一个 G。
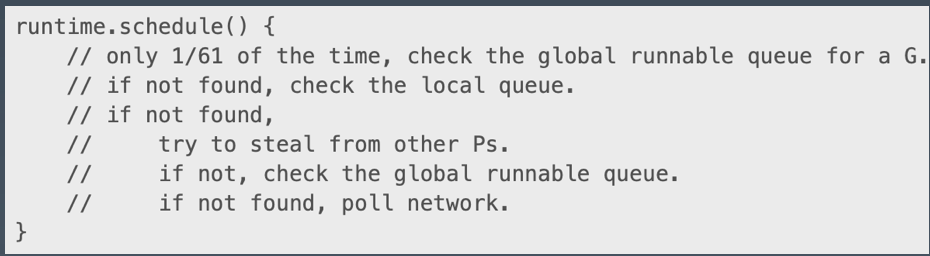
5. 发生syscall
- 调用 syscall 后会解绑 P,然后 M 和 G 进入阻塞。
- 系统监视器 (system monitor),称为 sysmon,会定时扫描。在执行 syscall 时, 如果某个 P 的 G 执行超过一个 sysmon tick(10ms),就会把他设为 idle,重新调度给需要的 M,强制解绑。
- syscall结束后。如果在短时间内阻塞的 M 就唤醒了,那么 M 会优先来重新获取这个 P,能获取到就继续绑回去,这样有利于数据的局部性。找不到就找其他空闲的P,否则放回全局队列。
- PS:使用 syscall 写程序要认真考虑 pthread exhaust 问题。
6. 自旋的M
- 类型1:M 不带 P 的找 P 挂载(一有 P 释放就结合)
- 类型2:M 带 P 的找 G 运行(一有 runable 的 G 就执行)
总结
- 单一全局互斥锁(Sched.Lock)和集中状态存储
- G 被分成全局队列和 P 的本地队列,全局队列依旧是全局锁,但是使用场景明显很少,P 本地队列使用无锁队列,使用原子操作来面对可能的并发场景。
- Goroutine 传递问题
- G 创建时就在 P 的本地队列,可以避免在 G 之间传递(窃取除外),G 对 P 的数据局部性好; 当 G 开始执行了,系统调用返回后 M 会尝试获取可用 P,获取到了的话可以避免在 M 之间传递。而且优先获取调用阻塞前的 P,所以 G 对 M 数据局部性好,G 对 P 的数据局部性也好。
- Per-M 持有内存缓存 (M.mcache)
- 内存 mcache 只存在 P 结构中,P 最多只有 GOMAXPROCS 个,远小于 M 的个数,所以内存没有过多的消耗。


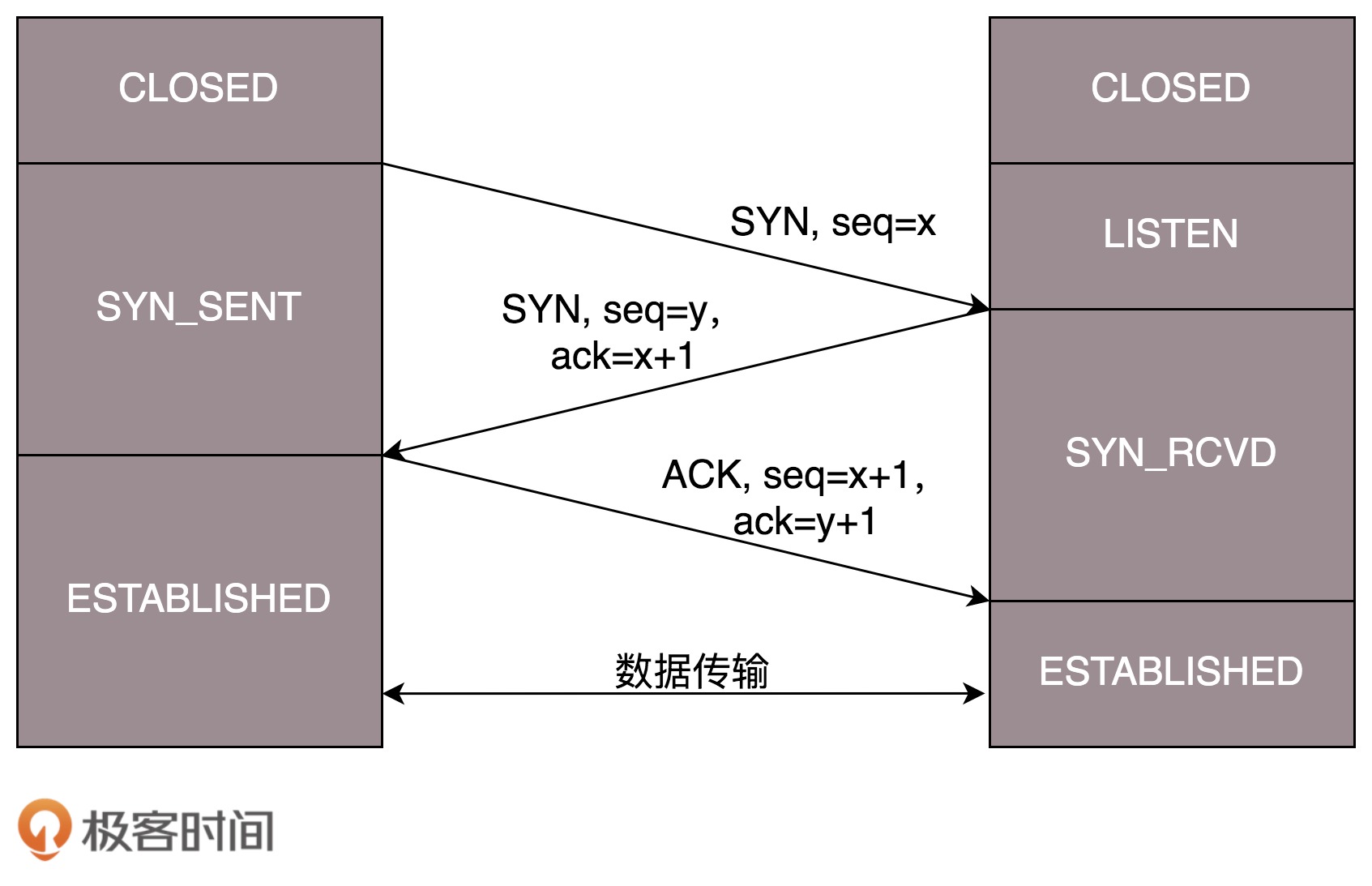
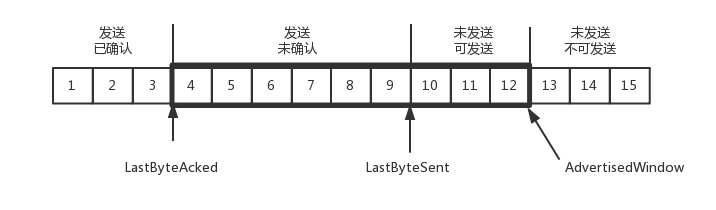
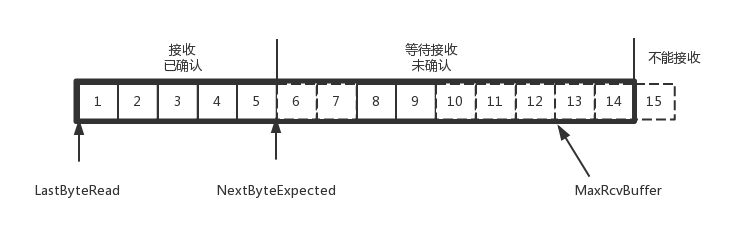
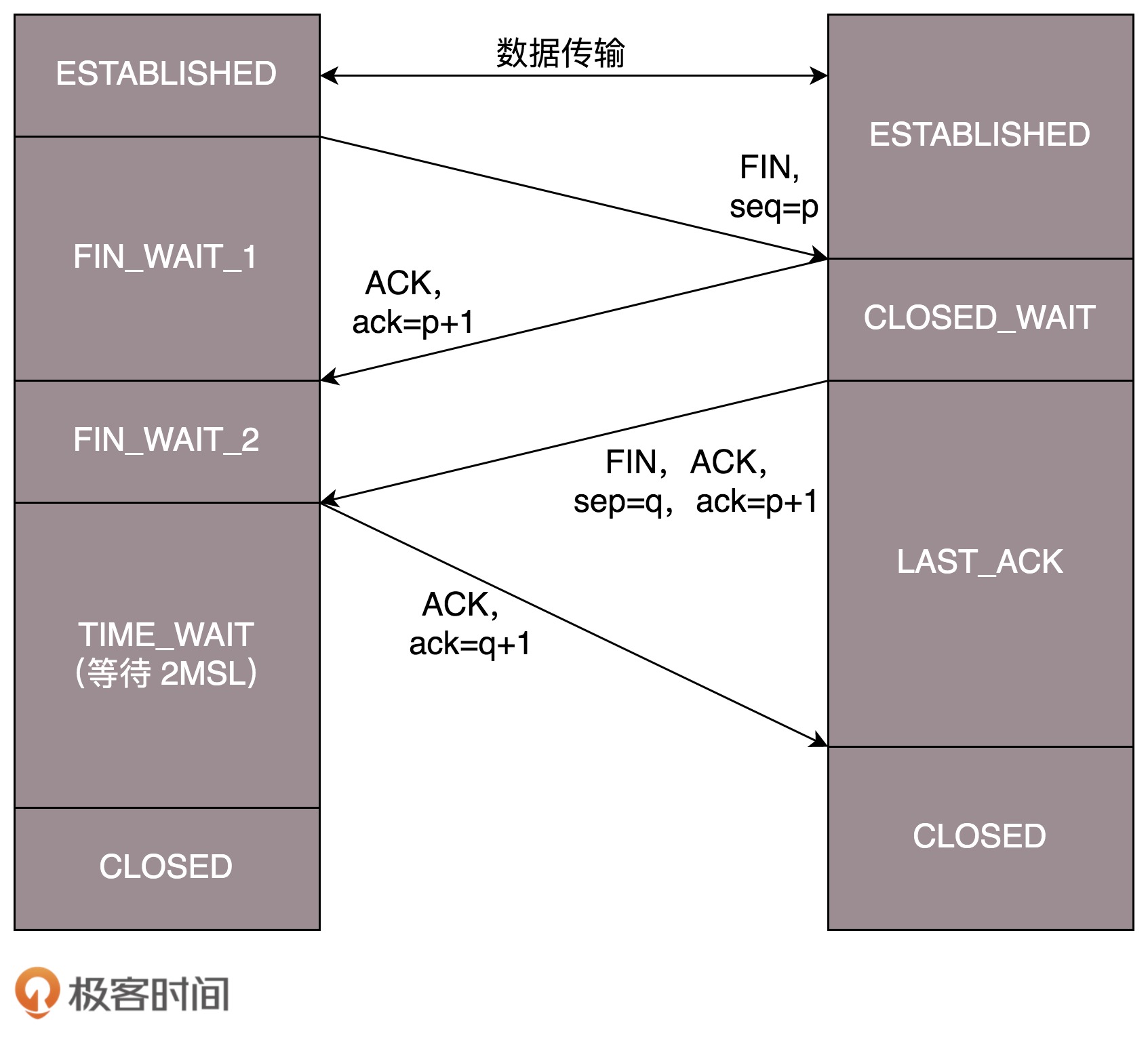 等待的时间设为 2MSL,MSL 是 Maximum Segment Lifetime,报文最大生存时间
等待的时间设为 2MSL,MSL 是 Maximum Segment Lifetime,报文最大生存时间