安装
- 安装配置JAVA及其环境变量
1
2export JAVA_HOME=/usr/local/java/jdk-12.0.1
export PATH=$PATH:${JAVA_HOME}/bin
如果是ubuntu,需要将JAVA_HOME变量配置到~/.bashrc,这篇文章所说,因为hadoop运行的时候是无登录的。
配置ssh登录
1
2ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys解压hadoop,~/.bashrc 添加环境变量
1
2
3export HADOOP_HOME=/etc/hadoop-3.1.2/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"etc/hadoop/hadoop-env.sh添加
1
2
3
4
5
6export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"etc/hadoop/core-site.xml添加
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/</value>
</property>
</configuration>etc/hadoop/hdfs-site.xml添加
1
2
3
4
5
6<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>格式化hdfs
1
bin/hdfs namenode -format
启动
1
2
3sbin/start-dfs.sh
sbin/stop-dfs.sh #关闭
jps #检查是否启动正常打开 http://localhost:9870 可以看见Hadoop的管理页面
Hadoop的组成
Hadoop 生态是一个庞大的、功能齐全的生态,但是围绕的还是名为 Hadoop 的分布式系统基础架构,其核心组件由四个部分组成,分别是:Common、HDFS、MapReduce 以及 YARN。
- Common 是 Hadoop 架构的通用组件;
- HDFS 是 Hadoop 的分布式文件存储系统;
- MapReduce 是Hadoop 提供的一种编程模型,可用于大规模数据集的并行运算;
- YARN 是 Hadoop 架构升级后,目前广泛使用的资源管理器。
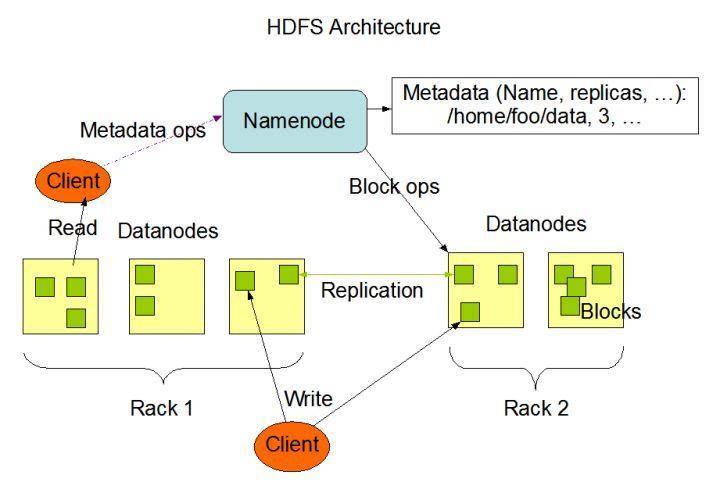
NameNode
- NameNode 是管理文件系统命名空间的主服务器,用于管理客户端对文件的访问,执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定了Block 到 DataNode 的映射。
- NameNode 做着有关块复制的所有决定,它定期从群集中的每个 DataNode 接收 Heartbeat 和 Blockreport。收到 Heartbeat 意味着 DataNode正常运行,Blockreport 包含 DataNode 上所有块的列表。
- 文件系统的元数据(MetaData)也存储在 NameNode 中,NameNode 使用名为 EditLog 的事务日志来持久记录文件系统元数据发生的每个更改。
- 整个文件系统命名空间(包括块到文件和文件系统属性的映射)存储在名为 FsImage 的文件中。 FsImage 也作为文件存储在 NameNode 的本地文件系统中。
DataNode
DataNode 通常是群集中每个节点一个,用于存储数据,负责提供来自文件系统客户端的读写请求。并且还会根据 NameNode 的指令执行块创建,删除和复制。
Hadoop生态圈
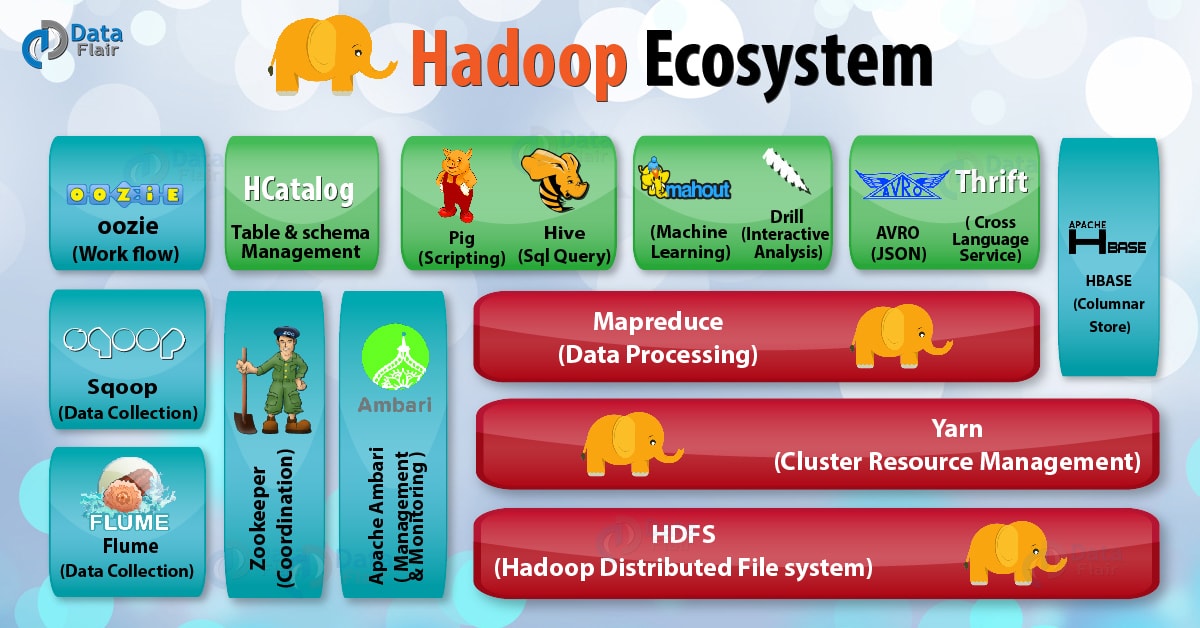

- HBase:来源于Google的BigTable;是一个高可靠性、高性能、面向列、可伸缩的分布式数据库。
- Hive:是一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
- ZooKeeper:来源于Google的Chubby;它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度。
- Ambari:Hadoop管理工具,可以快捷地监控、部署、管理集群。
- Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
- Mahout:一个可扩展的机器学习和数据挖掘库。
参考:
Hadoop: Setting up a Single Node Cluster.
Hadoop – 1. 从零搭建HDFS
Hadoop入门(一)之Hadoop伪分布式环境搭建
hadoop和大数据的关系?和spark的关系?