基本组成
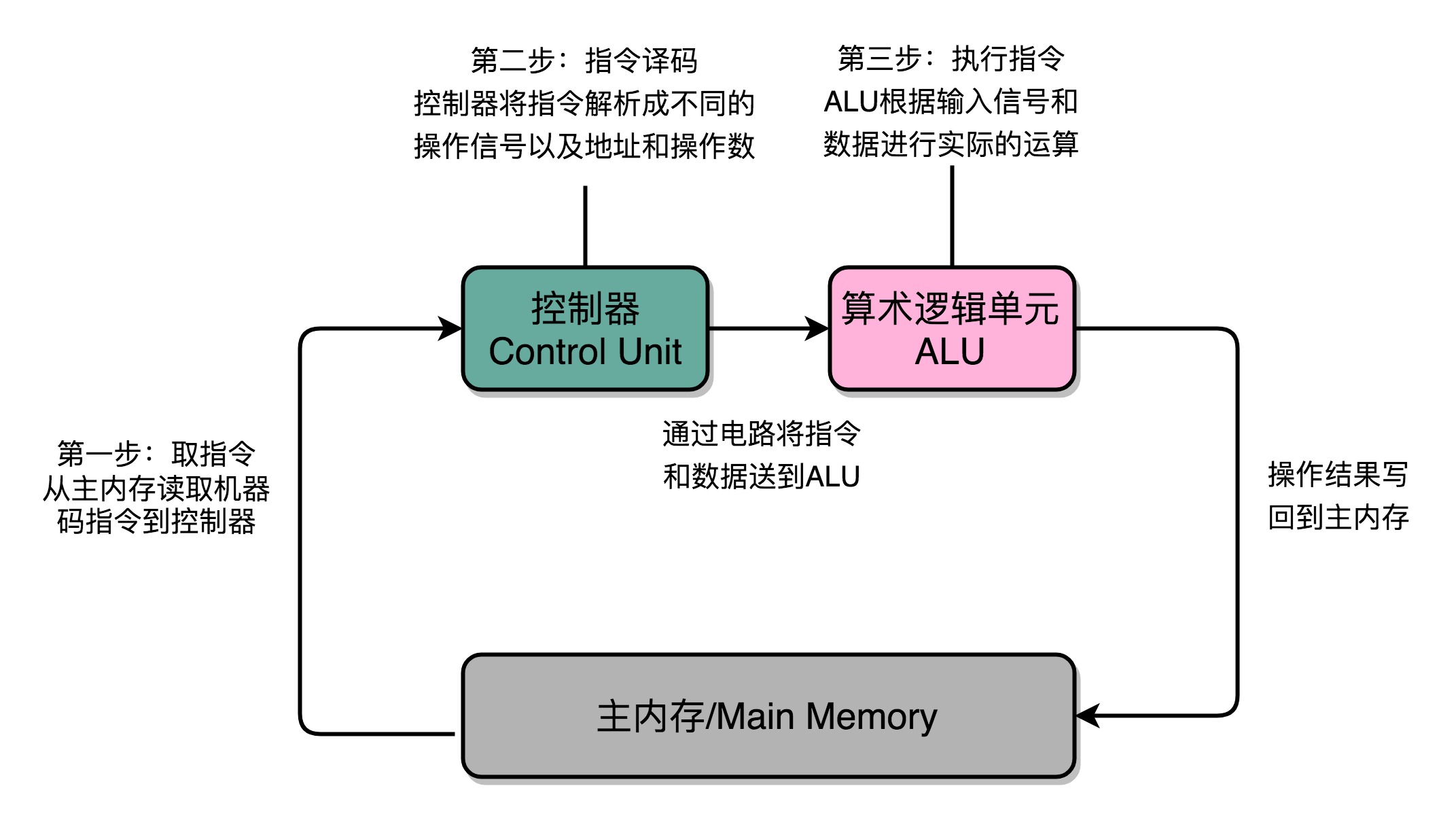
- 冯·诺伊曼体系结构:运算器、控制器、存储器、输入输出设备
- 计算机性能:
- CPU主频
- 响应时间:
- 吞吐率
- 程序的 CPU 执行时间 = 指令数×CPI(每条指令的平均时钟周期数)×Clock Cycle Time(时钟周期时间/主频)
- 计算机功耗
- 散热
- 能耗/电力
指令运算
计算机指令
机器码
- 不同的 CPU (Intel 的 CPU/ ARM 的 CPU)支持不同的计算机指令集。
- 编译–汇编–机器码(指令)
- 指令类型:
- 算术类指令
- 数据传输类指令
- 逻辑类指令
- 条件分支类指令
- 无条件跳转
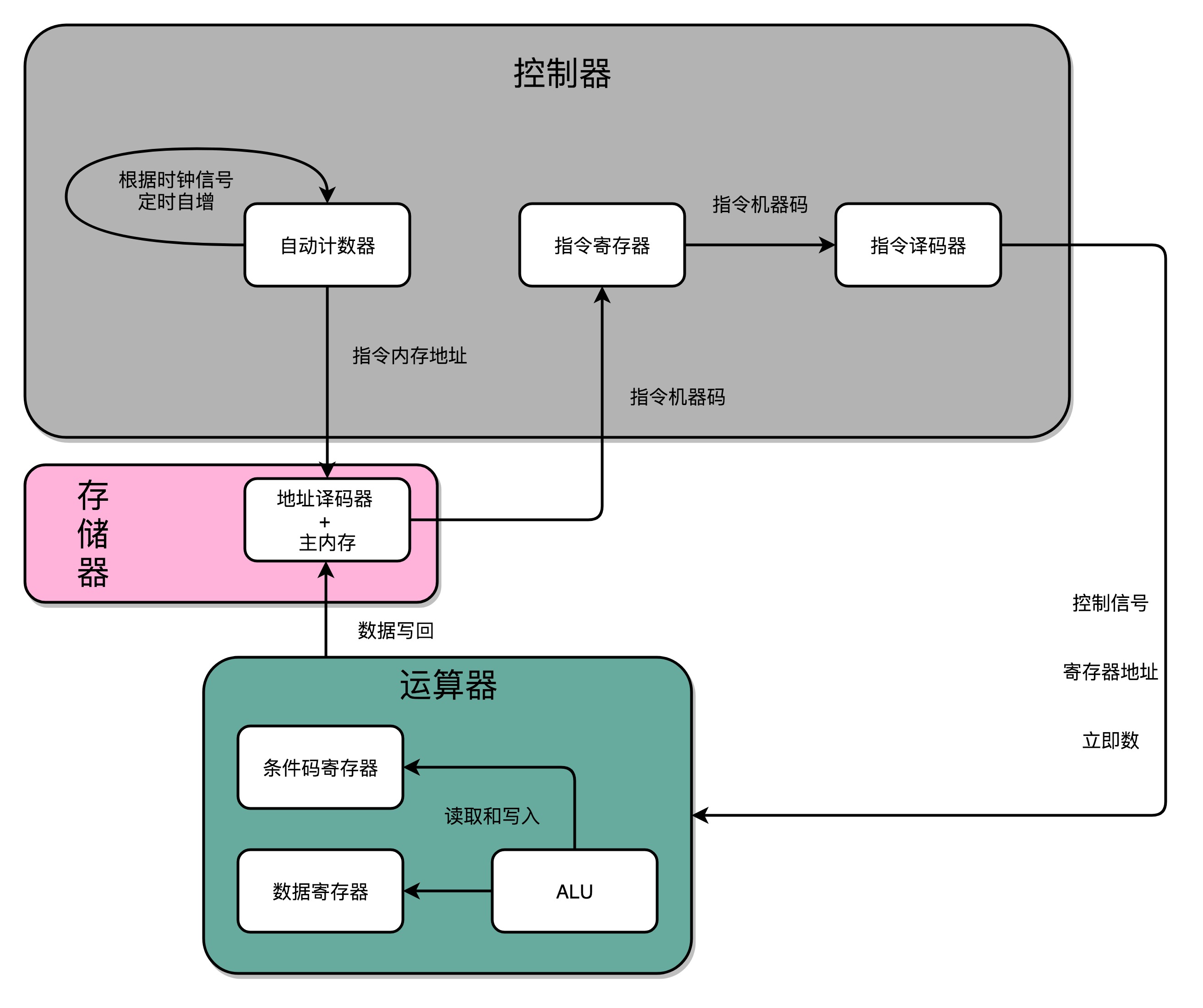
- 寄存器
- PC 寄存器(Program Counter Register),我们也叫指令地址寄存器
- 指令寄存器(Instruction Register),用来存放当前正在执行的指令
- 条件码寄存器(Status Register),用里面的一个一个标记位(Flag),存放 CPU 进行算术或者逻辑计算的结果
- 通用寄存器
- 程序运行:CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。
- 程序栈:
- 栈帧:整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧(Stack Frame)
- 压栈/出栈:push rbp 这个指令,就是在进行压栈。这里的 rbp 又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。push rbp 就把之前调用函数,也就是 main 函数的栈帧的栈底地址,压到栈顶。mov rbp, rsp 里,则是把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,而 rsp 始终会指向栈顶
- 函数内联:内联带来的优化是,CPU 需要执行的指令数变少了,根据地址跳转的过程不需要了,压栈和出栈的过程也不用了。
程序执行
- 不同操作系统下可执行文件的格式不一样。Linux 下的 ELF 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。
- 装载器:把对应的指令和数据加载到内存:
- 虚拟地址空间 映射 物理内存空间
- 分段:找出一段连续的物理内存和虚拟内存地址进行映射的方法
- 分段引起的内存碎片:内存交换,但每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上,是一个很慢的行为。
- 优化内存碎片:内存分页,和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。在 Linux 下,我们通常只设置成 4KB。
- 内存分页好处:
- 内存交换是以页为单位
- 在加载程序的时候,不再需要一次性都把程序加载到物理内存中。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。操作系统捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。
- 动态链接、静态链接
- 字符集(Unicode / ASCII)、字符编码(UTF-8、UTF-16、UTF-32)
- 门电路:创建 CPU 和内存的基本逻辑单元。我们的各种对于计算机二进制的“0”和“1”的操作,其实就是来自于门电路,叫作组合逻辑电路。
- 浮点数:随着指数位 e 的值的不同,小数点的位置也在变动
- 精度丢失:先对齐、再计算,其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。
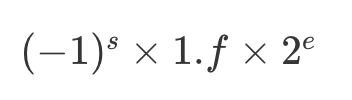
- 精度丢失:先对齐、再计算,其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。
处理器设计
- 指令周期:Fetch - Decode - Execute
- 一个指令周期,包含多个 CPU 周期(从内存里面读取一条指令的最短时间),而一个 CPU 周期包含多个时钟周期(CPU 的主频是由一个晶体振荡器来实现的,而这个晶体振荡器生成的电路信号,就是我们的时钟信号)。
- 所有 CPU 支持的指令,都会在控制器里面,被解析成不同的输出信号
- Cpu四种基本电路:
- ALU 这样的组合逻辑电路
- 用来存储数据的锁存器和 D 触发器电路
- 用来实现 PC 寄存器的计数器电路
- 以及用来解码和寻址的译码器电路。
- CPU工作流程:
 - 五级流水线:取指令(IF)- 指令译码(ID)- 指令执行(EX)- 内存访问(MEM)- 数据写回(WB)。保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了
- 流水线技术并不能缩短单条指令的响应时间这个性能指标,但是可以增加在运行很多条指令时候的吞吐率
Cpu冒险
- 结构冒险:来自于同一时钟周期不同的指令,要访问相同的硬件资源。
- 解决:现代的 CPU 虽然没有在内存层面进行对应的拆分,却在 CPU 内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部,使得我们的 CPU 在进行数据访问和取指令的时候,不会再发生资源冲突的问题了。
- 数据冒险:数据之间各种依赖。
- 解决:操作数前堆:通过在硬件层面制造一条旁路,让一条指令的计算结果,可以直接传输给下一条指令
- 解决流水线阻塞:乱序执行:在指令执行的阶段通过一个类似线程池的保留站,让系统自己去动态调度先执行哪些指令,等到在指令结果的最终提交的阶段,再通过重排序的方式。
- 控制冒险:动态分支预测:一级分支预测,或者叫 1 比特饱和计数的方法。其实就是认为,预测结果和上一次的条件跳转是一致的。
Cpu并行
- 超线程,其实是一个“线程级并行”的解决方案。它通过让一个物理 CPU 核心,“装作”两个逻辑层面的 CPU 核心,使得 CPU 可以同时运行两个不同线程的指令。
- SIMD 技术,则是一种“指令级并行”的加速方案,或者我们可以说,它是一种“数据并行”的加速方案,比如numpy
Cpu异常
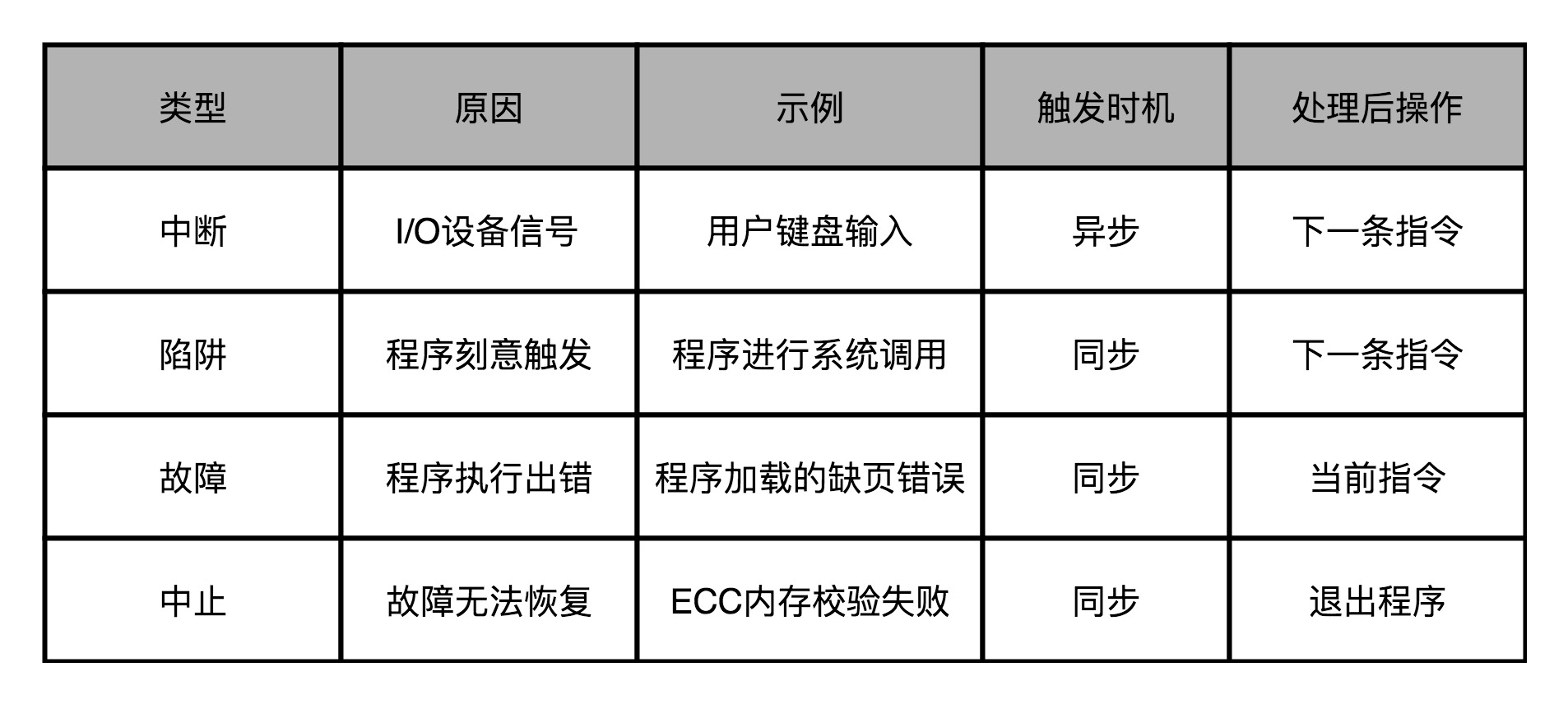
- 处理流程:处理流程,也就是上面所说的,“保存现场、异常代码查询、异常处理程序调用”
- 上下文切换:除了普通需要压栈的数据外,计算机还需要把所有寄存器信息都存储到栈里面去
- 除了本来程序压栈要做的事情之外,我们还需要把 CPU 内当前运行程序用到的所有寄存器,都放到栈里面
- 像陷阱这样的异常,涉及程序指令在用户态和内核态之间的切换。对应压栈的时候,对应的数据是压到内核栈里,而不是程序栈里
- 像故障这样的异常,在异常处理程序执行完成之后。从栈里返回出来,继续执行的不是顺序的下一条指令,而是故障发生的当前指令
- 硬中断即网卡利用信号“告知”CPU有包到来,CPU执行中断向量对应的处理程序,即收到的包拷贝到计算机的内存。然后“通知”软中断有任务需要处理,中断处理程序返回。
CISI & RISC
- RISC 的通过减少 CPI 来提升性能,而 CISC 通过减少需要的指令数来提升性能。
- 通过指令译码器和 L0 缓存的组合,使得这些指令可以快速翻译成 RISC 风格的微指令
存储与I/O
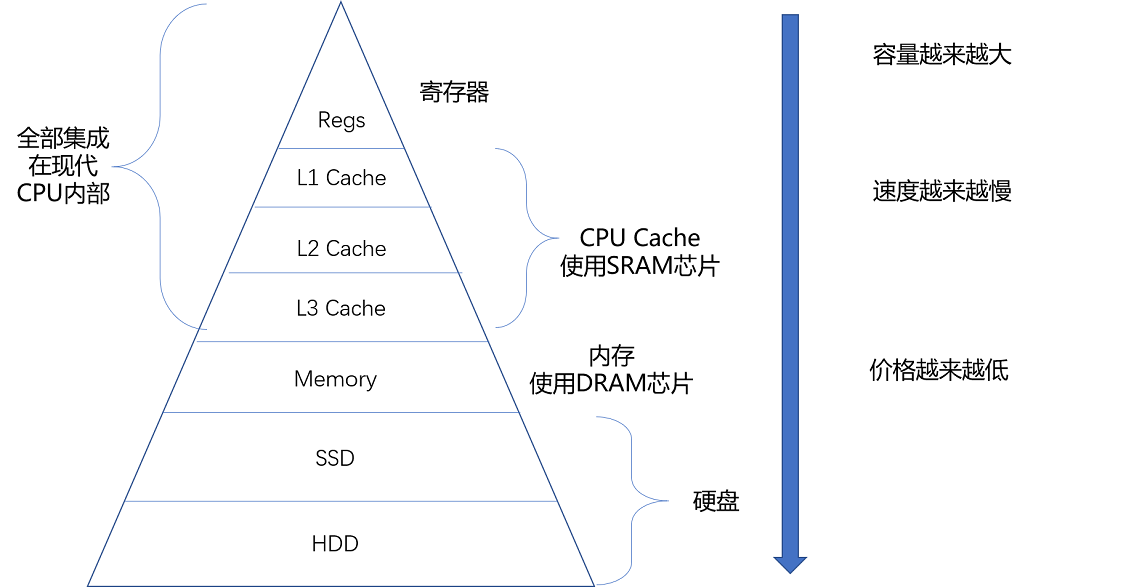
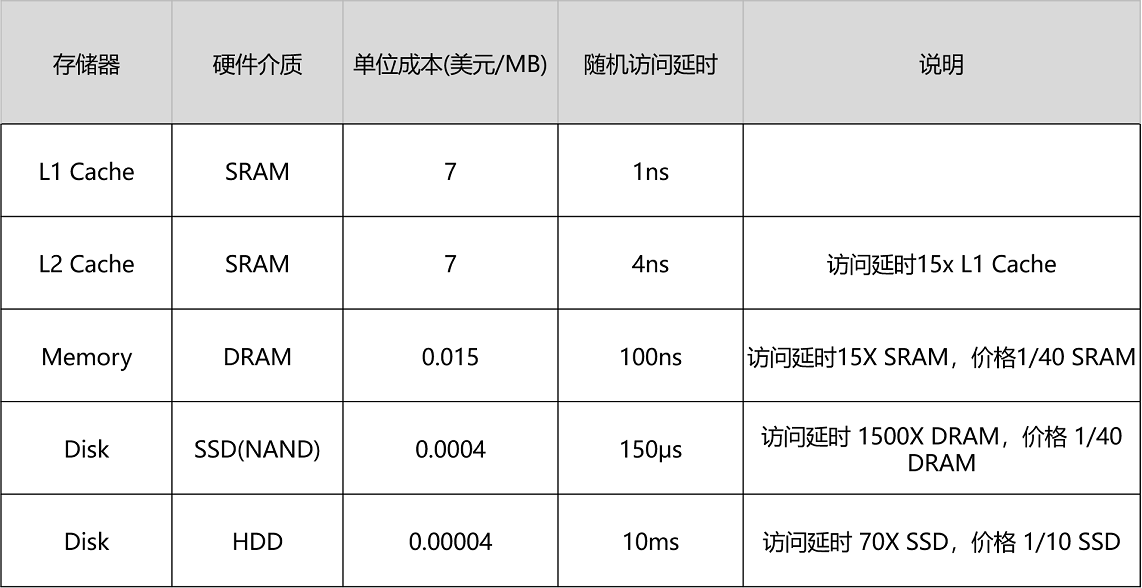
- 各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。
- 优化思路—局部性原理:
- 时间局部性:如果一个数据被访问了,那么它在短时间内还会被再次访问
- 如果一个数据被访问了,那么和它相邻的数据也很快会被访问
- Cache Line(缓存块/缓存行):CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的,64 位 Intel CPU 的计算机中大小通常是 64 字节。
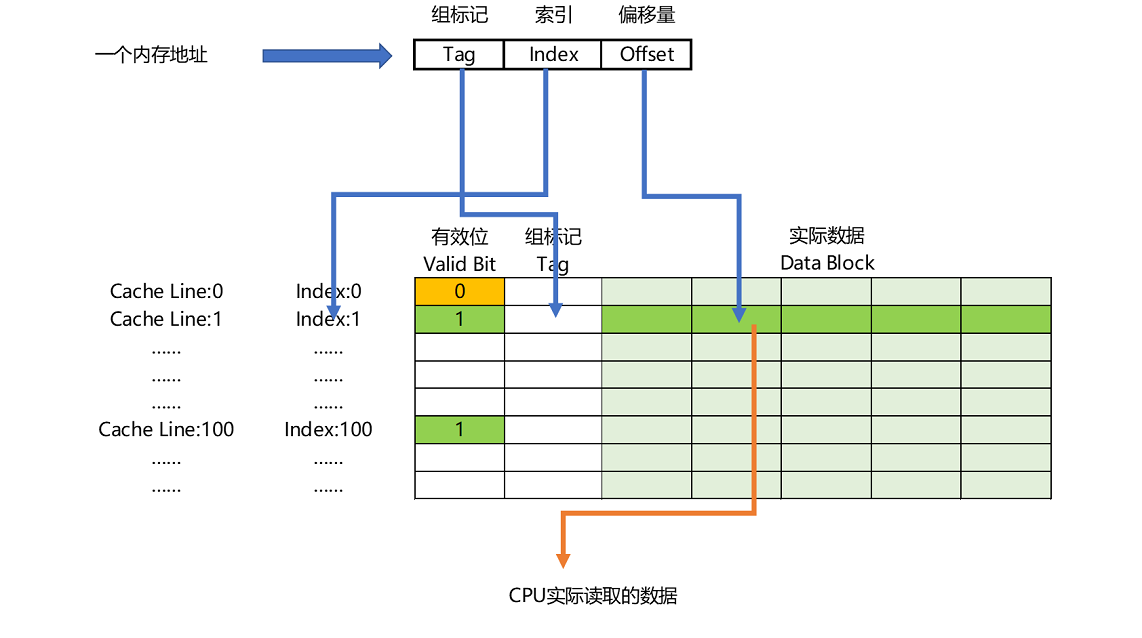
- 一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的 Data Block 中定位对应字的位置偏移量。
- 直接映射法:
- 写入策略
- 写直达:写入前,如果数据已经在 Cache 里面了,我们先把数据写入更新到 Cache 里面,再写入到主内存里面;如果数据不在 Cache 里,我们就只更新主内存
- 写回:果发现我们要写入的数据,就在 CPU Cache 里面,那么我们就只是更新 CPU Cache 里面的数据。同时,我们会标记 CPU Cache 里的这个 Block 是脏(Dirty)的(与主存不一致)。如果Cache Block已经是脏的,先将脏数据写回主存,再将新数据写入Cache Block
- 实现一致性需要满足条件:写传播、事务串行化
- 总线嗅探
- MESI协议:
- Cache Line 的四个不同的标记
- M:代表已修改(Modified):Cache Block 里面的内容我们已经更新过了,但是还没有写回到主内存里面
- E:代表独占(Exclusive):干净的,在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。
- S:代表共享(Shared)::干净的,在独占状态下的数据,如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态。
- I:代表已失效(Invalidated):Cache Block 里面的数据已经失效了
- RFO(request for ownership):在共享状态下,当我们想要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,然后再更新当前 Cache 里面的数据。
- Cache Line 的四个不同的标记
- False Sharing:
- A B 两个对象在内存上被连续的创建在一起,假若这两个对象都很小,小于一个 Cache Line 大小,那他们可能会共用同一个 Cache Line。如果再有两个线程 Thread 1 和 Thread 2 会去操作这两个对象,我们从代码角度保证 Thread 1 只会操作 A,而 Thread2 只会操作 B。那按道理这两个 Thread 访问 A B 不该有相互影响,都能并行操作。但现在因为它俩刚好在同一个 Cache Line 内,就会出现 A B 对象所在 Cache Line 在两个 CPU 上来回搬迁的问题。
- 内存屏障:写屏障是一种机制,用于强制执行对计算机系统中存储系统的一系列写入操作。
- Write Barrier:其作用是将 Write Barrier 之前所有操作的 Cache Line 都打上标记,Barrier 之后的写入操作不能直接操作 Cache Line 而也要先写 Store Buffer 去,但不用打特殊标记。等 Store Buffer 内带着标记的写入因为收到 Invalidate Ack 而能写 Cache Line 后,这些没有打标记的写入操作才能写入 Cache Line。
- Read Barrier:CPU 看到 Read Barrier 只是标记 Invalidate Queue 上的 Cache Line,之后继续执行别的指令,直到看到下一个 Load 操作要从 Cache Line 里读数据了,CPU 才会等待 Invalidate Queue 内所有刚才被标记的 Cache Line 都处理完才继续执行下一个 Load。
- https://nextfe.com/memory-barrier/
虚拟内存
- 内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置
- 页表
- 一个内存地址分成页号(Directory)和偏移量(Offset)两个部分。映射表需要保留虚拟内存地址的页号和物理内存地址的页号之间的映射关系就可以了
- 多级页表:多级页表就像是一颗树。因为一个进程的内存地址相对集中和连续,所以采用这种页表树的方式,可以大大节省页表所需要的空间
- 多级页表节约内存:https://www.polarxiong.com/archives/多级页表如何节约内存.html
- TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)。这块缓存存放了之前已经进行过地址转换的查询结果。
- 在 CPU 芯片里面,我们封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。
- 内存保护措施:可执行空间保护,地址空间布局随机化。
总线
- CPU 的双独立总线
- 本地总线(Local Bus):与高速缓存通信
- 速度相对较慢的前端总线(Front-side Bus):与主内存以及输入输出设备通信的
- 总线不能同时给多个设备提供通信功能
IO wait
- 如何查看:
- top :%cpu wa指标:CPU 等待 IO 完成操作花费的时间占 CPU 的百分比
- iostat:tps 指标,对应硬盘的 IOPS 性能。而 kB_read/s 和 kB_wrtn/s 指标,对应着我们的数据传输率
- iotop: 查看io占用进程
- IOPS 和 DTR(Data Transfer Rate,数据传输率)才是输入输出性能的核心指标。
- https://louwrentius.com/understanding-iops-latency-and-storage-performance.html
硬盘
- 机械硬盘的硬件,主要由盘面、磁头和悬臂三部分组成。实际的一次对于硬盘的访问,需要把盘面旋转到某一个“几何扇区”,对准悬臂的位置。然后,悬臂通过寻道,把磁头放到我们实际要读取的扇区上。
- 随机数据的访问速度= 旋转盘面的平均延时 + 移动悬臂的寻道时间
- 7200 转机械硬盘的 IOPS,只能做到 100 左
- SSD 的物理原理,也就是“电容 + 电压计”的组合。适合读多写少的场景。SSD寿命取决于擦除的次数。
- FTL 这个映射层,使得操作系统无需关心物理块的擦写次数,而是由 FTL 里的软件算法,来协调到底每一次写入应该磨损哪一块。
- SSD 这个需要进行垃圾回收的特性,使得我们在写入数据的时候,会遇到写入放大
- DMA:DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)
- 只有主设备(CPU)可以发起数据传输,如果从设备(I/O设备)需要发起数据传输,只能发送一个控制信号到主设备。
- 而DMAC是主设备也是从设备,由CPU通知DMAC源地址的初始值以及传输时候的地址增减方式、目标地址初始值和传输时候的地址增减方式、要传输的数据长度,由DMAC搬运数据。
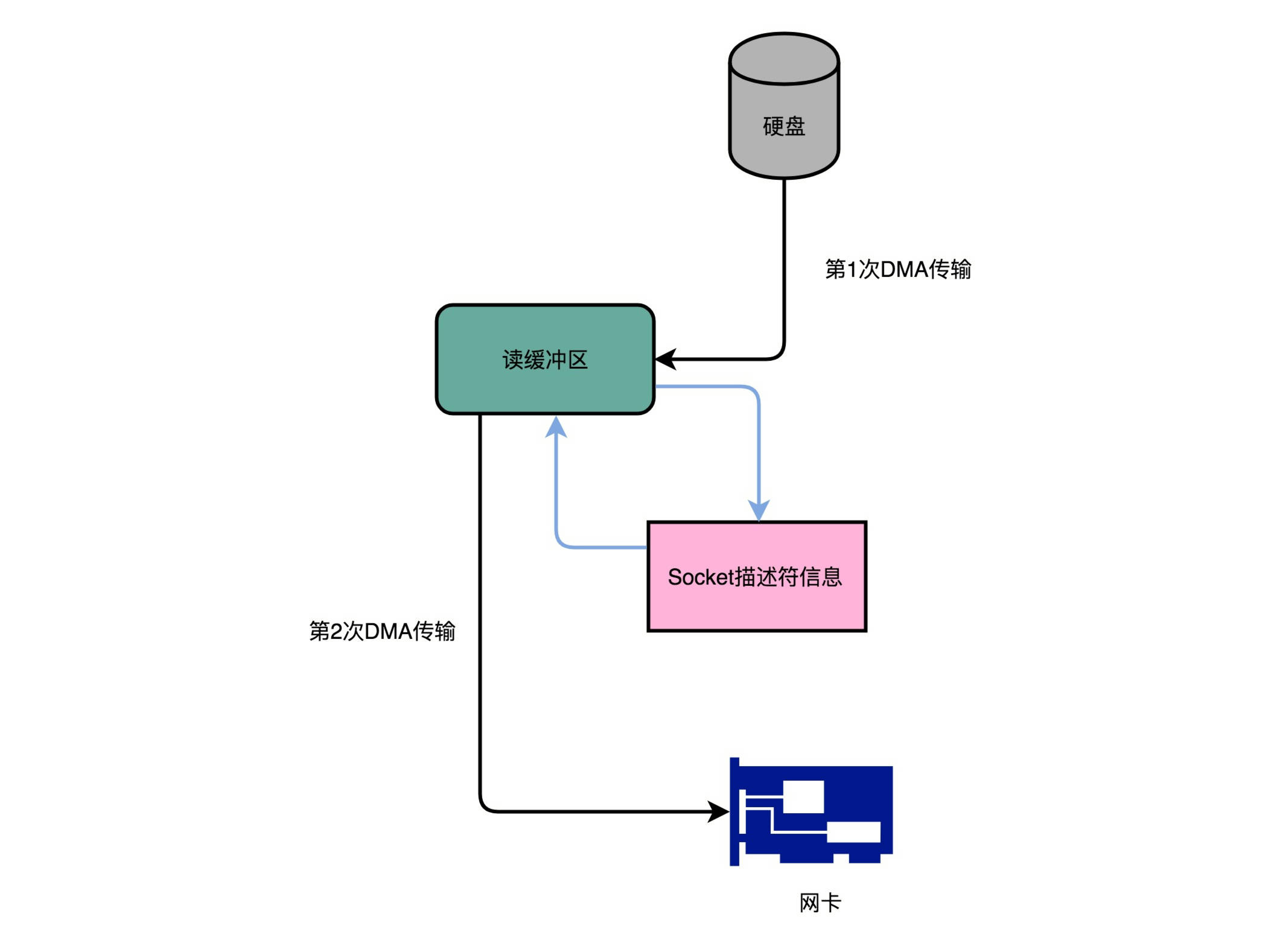
- Kafka的零拷贝:Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。我们的数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。
- 通过 DMA,从硬盘直接读到操作系统内核的读缓冲区里面。
- 根据 Socket 的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。
- http://notes.stephenholiday.com/Kafka.pdf
应用
Disruptor 消息队列
- 利用Cache Line:Disruptor 很取巧地在需要频繁高速访问的变量,也就是 RingBufferFields 里面的 indexMask 这些字段前后,各定义了 7 个没有任何作用和读写请求的 long 类型的变量。这样,无论在内存的什么位置上,这些变量所在的 Cache Line 都不会有任何写更新的请求。我们就可以始终在 Cache Line 里面读到它的值,而不需要从内存里面去读取数据,也就大大加速了 Disruptor 的性能。
- 利用数组而不是链表:RingBuffer 底层的数据结构则是一个固定长度的数组。这个数组不仅让我们更容易用好 CPU Cache,对 CPU 执行过程中的分支预测也非常有利。
- 无锁队列:通过 CAS 这样的操作,去进行序号的自增和对比,使得 CPU 不需要获取操作系统的锁。因为单指令是原子性操作。