本文整理周爱民在Qcon中《在JavaScript中的并行语言特性》演讲。
JavaScritp中的执行栈
执行栈,也就是在其它编程语言中所说的“调用栈”,是一种拥有 LIFO(后进先出)数据结构的栈,被用来存储代码运行时创建的所有执行上下文。
引擎会执行那些执行上下文位于栈顶的函数。当该函数执行结束时,执行上下文从栈中弹出,控制流程到达当前栈中的下一个上下文。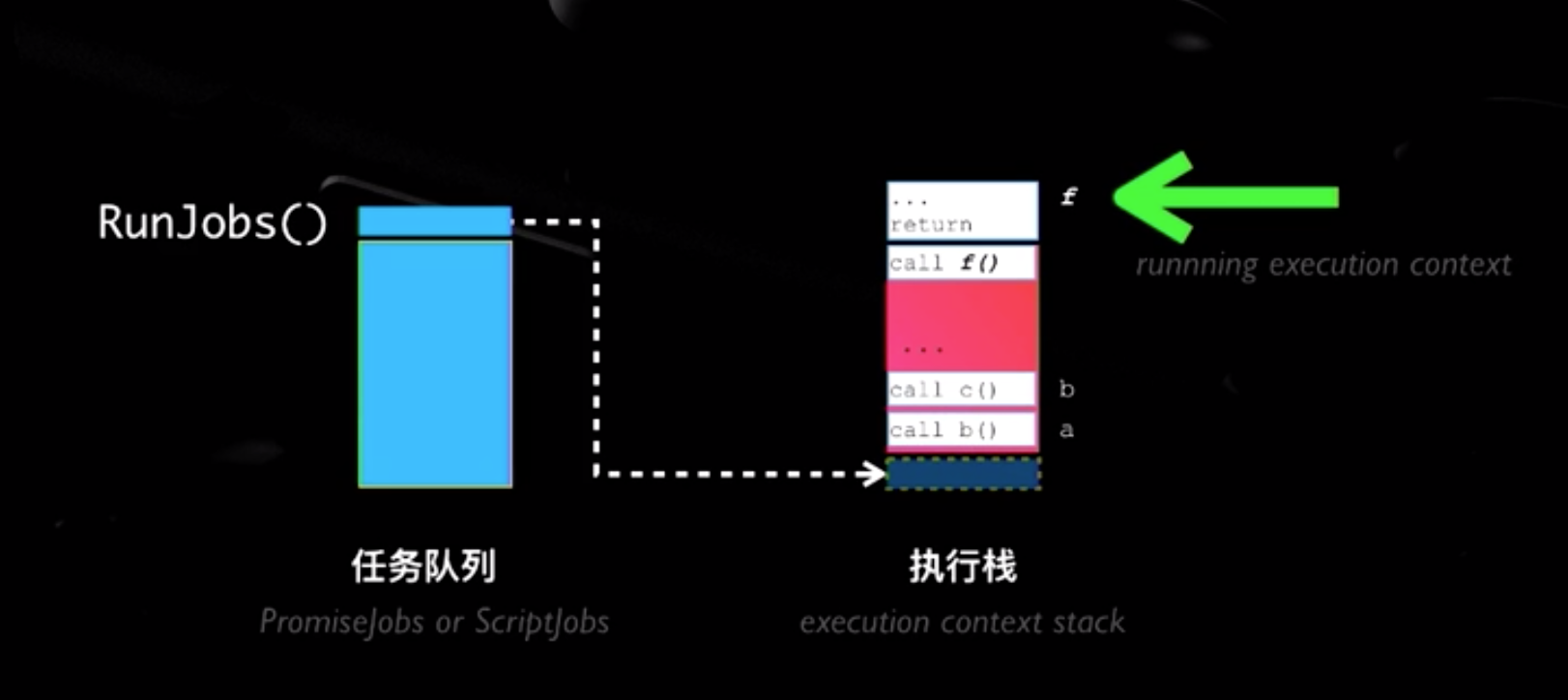
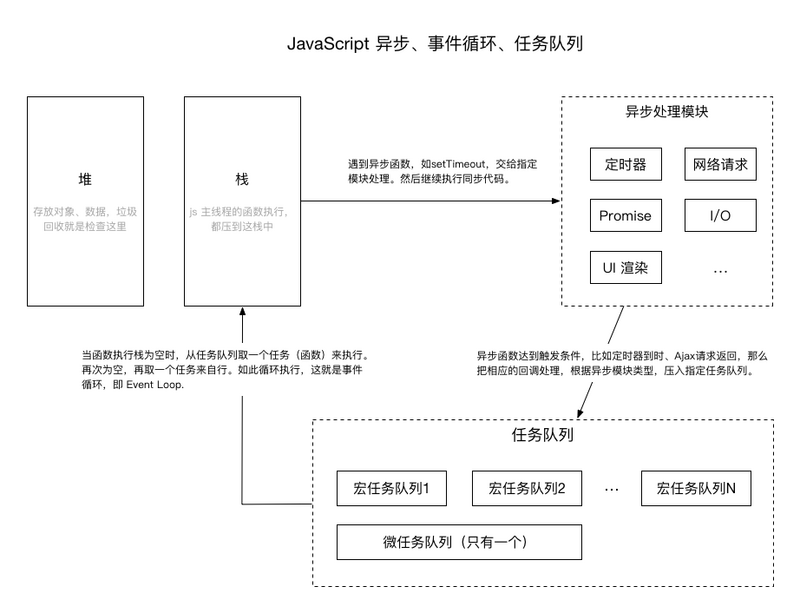
Event Loop:当执行栈为空时,从任务队列(RUN JOB)取一个任务执行。再次为空时,再从队列取一个任务,如此循环往复。
当一个函数上下文被从执行栈移走时,相当于函数被挂起了。
Promise是如何处理的
Promise的数据结构:
先看一个hello world例子1
2
3// 数据就绪,然后做点什么
// Hello world字符串就绪后,然后执行console.log
Promise.resolve("Hello world").then(console.log);
当then函数,如:1
aPromise.then(func1,func2)
func1、func2 会传入上图 Reaction列表里,两个fun产生的结果值将会产生新的Promise对象,1
bPromise = aPromise.then(func1,func2)
bPromise与func1 func2无关,只与它们产生的结果有关系。
然后Promise.resolve(x) 约等于1
2
3
4
5var p = new Promise();
// 创建新的置值器
var [resolve, reject] = ... of p;
resolve(x); // 相当于 p[[result]] = x;
return p;
如果x不是一个简单的值,而是一个promise本身,假设 p2 = Promise.resolve(p)1
2
3
4var p2 = new Promise()
var [resolve, reject] = ... of p2;
p.then(resolve, reject); // resolve(p);
return p2;
上面提到,当函数被走执行栈移走时,函数会被挂起,Promise就是其中一个例子,会导致函数被挂起。Promise在执行栈被初始化后,被扔会任务队列,所以Promise时并行执行的。当数据就绪后,执行栈再次从任务队列调用回来,Promise就被唤起了。
await是如何处理的
1 | async function foo(){ |
await与Promise相似,也会导致函数被挂起。
- 创建一个新的Promise px, 其resolve,reject函数对将用作参数调用p.then(),即Promise.resolve(p)
- 为px创建一对onFullfilled, onRejected响应函数,使指向当前栈顶上下文。
- 将响应函数onXXX作为参数调用px.then(),使onXXX函数添加到任务队列。
- 将当前执行上下文从栈顶移除。
至于为什么要创建px,我觉得是为了在onFullfilled函数绑定上下文,参考这里
语言特性与架构
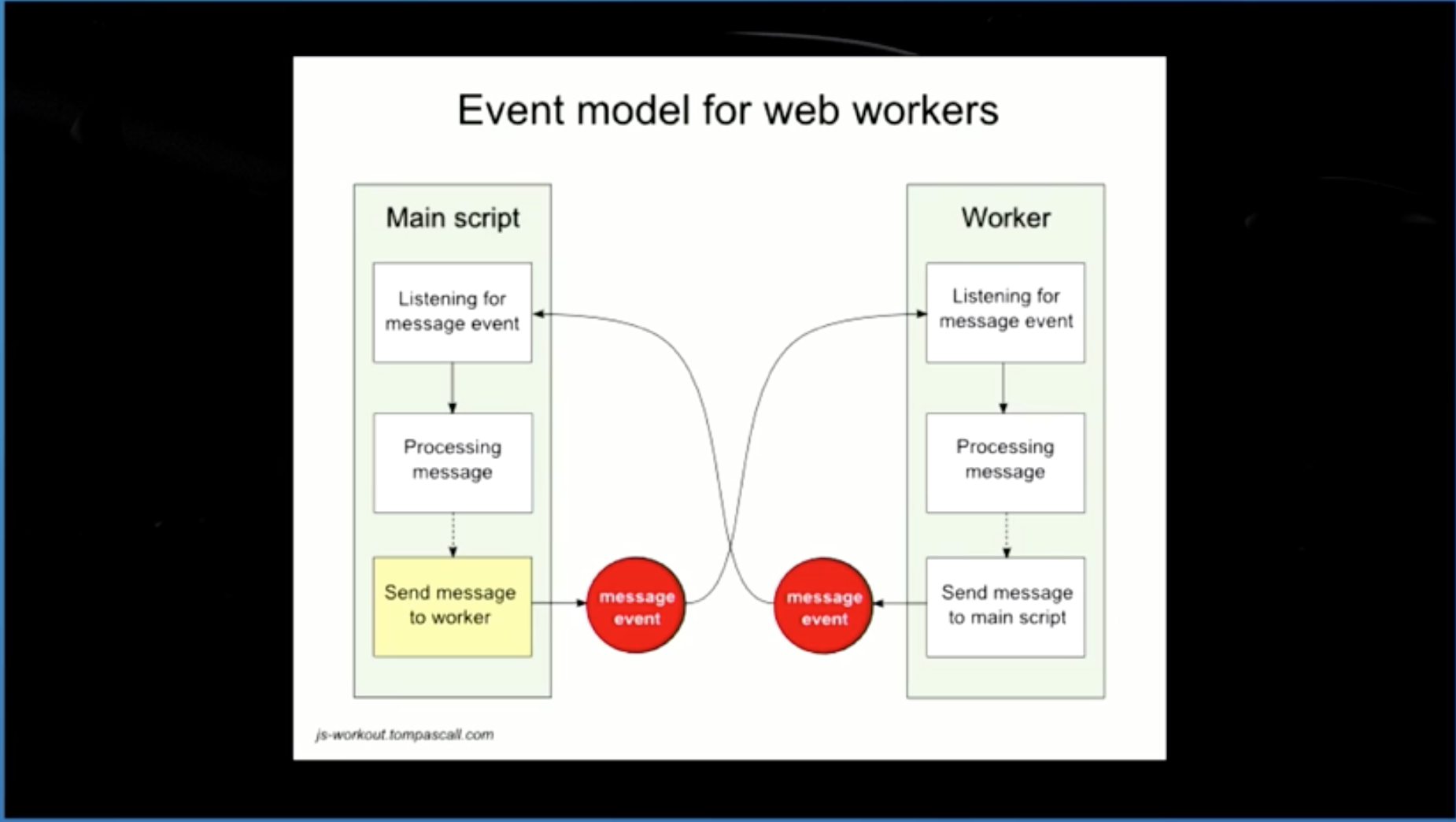
在顶层第一行代码使用await会导致主线程被挂起,在ECMA2017创建了工作线程。NodeJs中也有工作线程的概念。主线程与工作线程通过有消息通讯,通过sab共享内存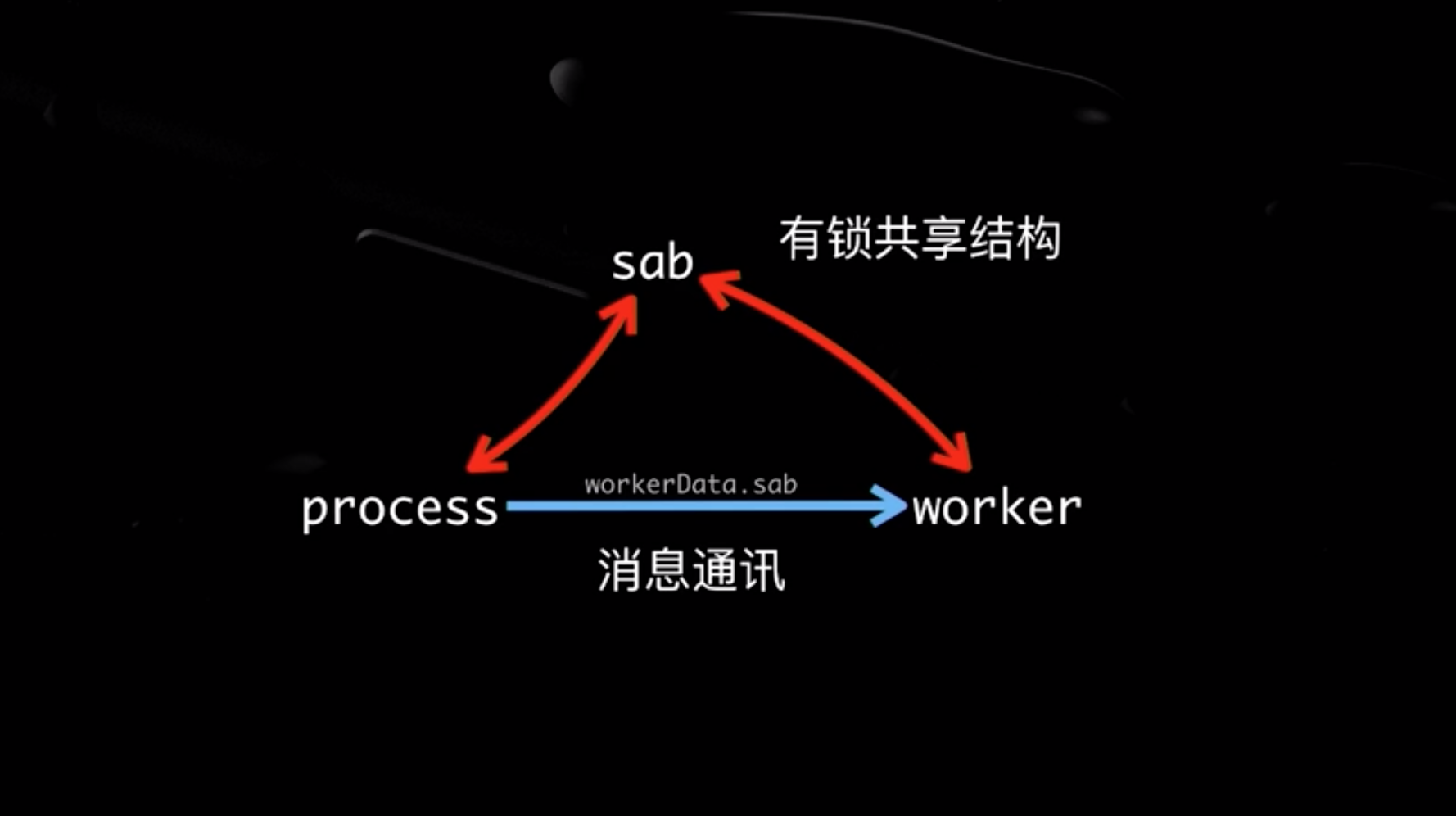
这种解决方案与分布式环境下并发解决问题是一致的。集群中消息通讯、任务调度、资源管理模型也是语言中底层线程设计思想、解决的问题也是一样的。