性能分析
- 基本技术如 IPython 的 timeit 魔法函数、time.time()、以及一个计时修饰器,使用这些技术来了解语句和函数的行为。
- 内置工具如 cProfile,了解代码中哪些函数耗时最长,并用 runsnake 进行可视化。
- line_profiler 工具,对选定的函数进行逐行分析,其结果包含每行被调用的次数以及每行花费的时间百分比。
- memory_profiler 工具,以图的形式展示RAM的使用情况随时间的变化,解释为什么某个函数占用了比预期更多的 RAM。
- Guppy 项目的 heapy 工具,查看 Python 堆中对象的数量以及每个对象的大小,这对于消灭奇怪的内存泄漏特别有用。
- dowser 工具,通过Web浏览器界面审查一个持续运行的进程中的实时对象。
- dis 模块,查看 CPython 的字节码,了解基于栈的 Python 虚拟机如何运行。
- 单元测试,在性能分析时要避免由优化手段带来的破坏性后果。
数据结构影响
列表和元组就类似于其它编程语言的数组,主要用于存储具有内在次序的数据;
- 高效搜索必需的两大要素是排序算法和搜索算法。Python 列表有一个内建的排序算法使用了Tim排序。
- 动态数组支持 resize 操作,可以增加数组的容量。当一个大小为N的列表第一次需要添加数据时,Python会创建一个新的列表,足够存放原来的N个元素以及额外需要添加的元素。
- 元组固定且不可变。这意味着一旦元组被创建,和列表不同,它的内容无法被修改或它的大小也无法被改变。
字典和集合就类似其它编程语言的哈希表/散列集,主要用于存储无序的数据。
- 新插入数据的位置取决于数据的两个属性:键的散列值以及该值如何跟其他对象比较。这是因为当我们插入数据时,首先需要计算键的散列值并掩码来得到一个有效的数组索引。
- 如果被占用,那么要找到新的索引,我们用一个简单的线性函数计算出一个新的索引,这一方法称为嗅探。Python的嗅探机制使用了原始散列值的高位比特。使用这些高位比特使得每一个散列值生成的下一可用散列序列都是不同的,这样就能帮助防止未来的碰撞。
- 当一个值从散列表中被删除时,我们不能简单地写一个NULL到内存的那个桶里。这是因为我们已经用NULL来作为嗅探散列碰撞的终止值。所以,我们必须写一个特殊的值来表示该桶虽空,但其后可能还有别的因散列碰撞而插入的值。
- 不超过三分之二满的表在具有最佳空间节约的同时依然具有不错的散列碰撞避免率。改大散列表的代价非常昂贵,但因为我们只在表太小时而不是在每一次插入时进行这一操作。
- Python 对象通常以散列表实现,因为它们已经有内建的hash和cmp函数。
- 每当 Python 访问一个变量、函数或模块时,都有一个体系来决定它去哪里查找这些对象。
- locals()数组
- globals()字典
- __builtin__对象(builtin中的一个 属性时,我们其实是在搜索它的 locals()字典)
迭代器、生成器
- 节约内存
- 延迟估值
矩阵与矢量计算
原生 Python 并不支持矢量操作,因为 Python 列表存储的不是实际的数据,而是对实际数据的引用。在矢量和矩阵操作时,这种存储结构会造成极大的性能下降。
Numpy 能够将数据连续存储在内存中并支持数据的矢量操作,在数据处理方面,它是高性能编程的最佳解决方案之一。
Numpy 带来性能提升的关键在于,它使用了高度优化且特殊构建的对象,取代了通用的列表结构来处理数组,由此减少了内存碎片;此外,自动矢量化的数学操作使得矩阵计算非常高效。
Numpy 在矢量操作上的缺陷是一次只能处理一个操作。例如,当我们做 A B + C 这样的矢量操作时,先要等待 A B 操作完成,并保存数据在一个临时矢量中,然后再将这个新的矢量和 C 相加。
编译器
让你的代码运行更快的最简单的办法就是让它做更少的工作。编译器把代码编译成机器码,是提高性能的关键组成部分。
- Cython ——这是编译成C最通用的工具,覆盖了Numpy和普通的Python代码(需要一些C语言的知识)。
- Shed Skin —— 一个用于非Numpy代码的,自动把Python转换成C的转换器。
- Numba —— 一个专用于Numpy代码的新编译器。
- Pythran —— 一个用于Numpy和非numpy代码的新编译器。
- PyPy —— 一个用于非Numpy代码的,取代常规Python可执行程序的稳定的即时编译器。
密集型任务
- I/O 密集型:异步编程
- Gevent
- Tornado
- Asyncio
- CPU 密集型:多核 CPU 进行多进程
- Multiprocessing
- multiprocessing.Pool
- 内存共享
- multiprocessing.Manager()
- redis等中间件
- mmap
- Multiprocessing
集群与现场教训
- 集群带来的问题:
- 机器间信息同步的延迟
- 机器间配置与性能的差异
- 机器的损耗与维护
- 其它难以预料的问题
- 集群化解决方案:
- Parallel Python
- IPython Parallel
- NSQ


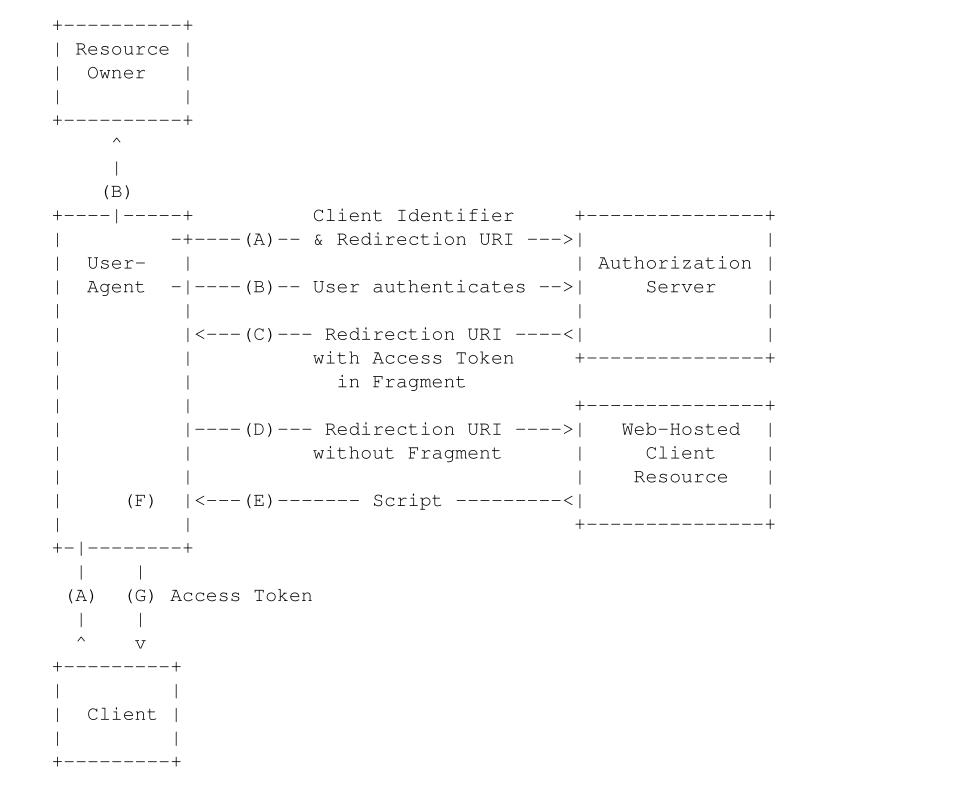
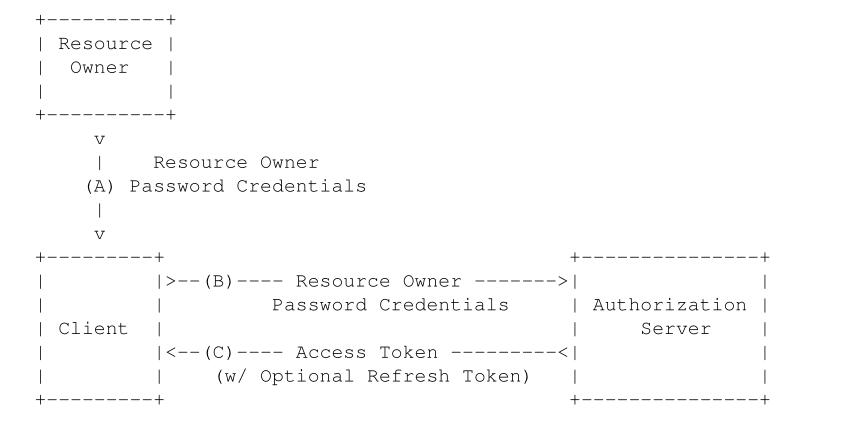 Client直接使用Resource owner提供的username和password来直接请求access_token(直接发起Access Token Request然后返回Access Token Response信息)。这种模式一般适用于Resource server高度信任第三方Client的情况下。
Client直接使用Resource owner提供的username和password来直接请求access_token(直接发起Access Token Request然后返回Access Token Response信息)。这种模式一般适用于Resource server高度信任第三方Client的情况下。 Client直接已自己的名义而不是Resource owner的名义去要求访问Resource server的一些受保护资源。
Client直接已自己的名义而不是Resource owner的名义去要求访问Resource server的一些受保护资源。


 利用自增序列的方案。
利用自增序列的方案。